
or why did the optimizer not select the index access path?
and what does TABLE_CACHED_BLOCKS actually do?
The Oracle Optimizer is complex. It takes the statistics it has about your data from the data dictionary (or dynamically generates them) and uses the information it has to determine the best way to access the data. Oracle generates a “COST”, a normalised number which describes the I/O and CPU requirement in terms of “single block reads”. This blog post will concentrate on one small aspect of that – index access.
The index is a lookup mechanism. In Oracle, the main index type is a balanced B-tree index, which looks rather like a Christmas Tree, a very short and very wide tree in most cases, much wide than the diagram below.
Oracle is able to lookup the value in the index based upon your predicates (WHERE clause) and navigate quickly, reading only a few blocks, to get the ROWID(s) of the table where the data exists. It then performs single block reads of those blocks by ROWID to get the data from the table, assuming that you are accessing more columns than exist in the index (if you are only accessing columns which exist in the index, the table look-up part does not happen, the cost is usually dramatically lower, and the access path extremely efficient.)
So, how does Oracle decide the COST of this operation? It looks at the amount of I/O (blocks) that is required, and adds a bit on for CPU consumption. It needs to read the index, then from each matching row read that table block. Each of those reads is a single block read. And this is the important part. How many blocks does the index think it will need to read from the table? How does it determine this?
So, the first row matched from the index reads the first table block. The 2nd row is then matched. Can the index pull the data from the black is had just read (and it therefore cached in memory), or does it need to read a new block from disk? Reading a new block is expensive whereas re-reading the same block for the data is very quick. To guess this, Oracle uses the information from DBA_IND_STATISTICS.CLUSTERING_FACTOR.
> desc DBA_IND_STATISTICS
Name Null? Type
----------------------- -------- ----------------
OWNER VARCHAR2(128)
INDEX_NAME VARCHAR2(128)
TABLE_OWNER VARCHAR2(128)
TABLE_NAME VARCHAR2(128)
PARTITION_NAME VARCHAR2(128)
PARTITION_POSITION NUMBER
SUBPARTITION_NAME VARCHAR2(128)
SUBPARTITION_POSITION NUMBER
OBJECT_TYPE VARCHAR2(12)
BLEVEL NUMBER
LEAF_BLOCKS NUMBER
DISTINCT_KEYS NUMBER
AVG_LEAF_BLOCKS_PER_KEY NUMBER
AVG_DATA_BLOCKS_PER_KEY NUMBER
CLUSTERING_FACTOR NUMBER
NUM_ROWS NUMBER
AVG_CACHED_BLOCKS NUMBER
AVG_CACHE_HIT_RATIO NUMBER
SAMPLE_SIZE NUMBER
LAST_ANALYZED DATE
GLOBAL_STATS VARCHAR2(3)
USER_STATS VARCHAR2(3)
STATTYPE_LOCKED VARCHAR2(5)
STALE_STATS VARCHAR2(3)
SCOPE VARCHAR2(7)
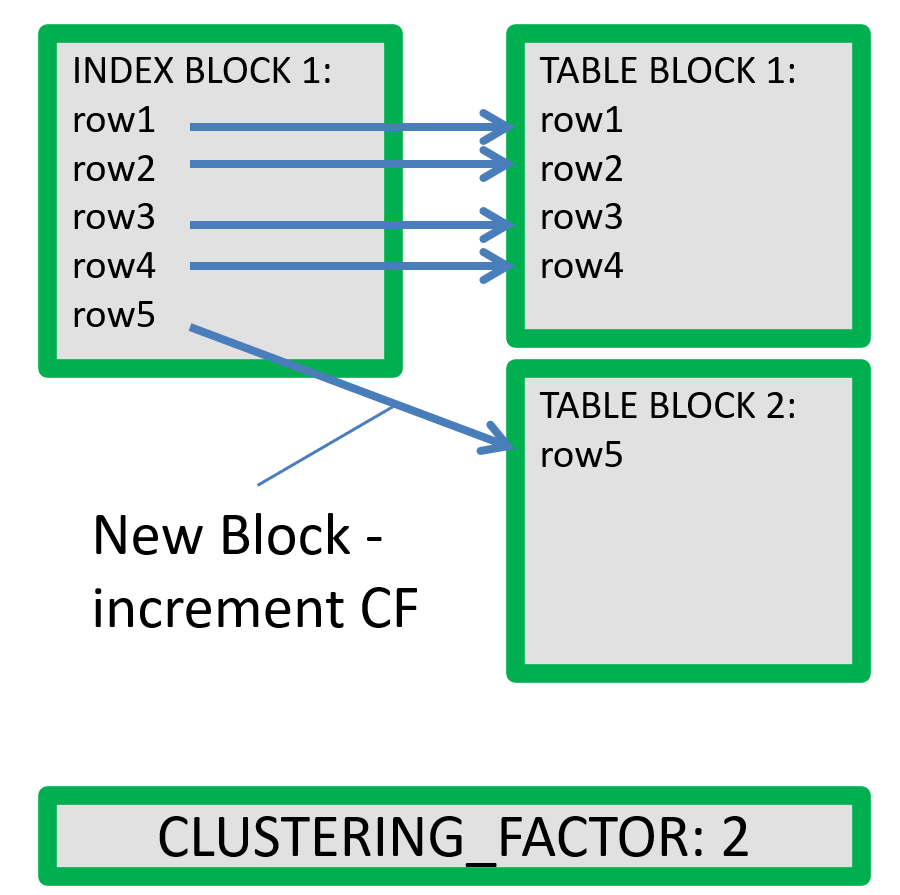
If the clustering factor is close to the number of BLOCKS in the table, the index is aligned to the table and lower cost to use.
If the clustering factor is close to the number of ROWS in the table, the index is NOT aligned to the table and therefore more expensive to use.
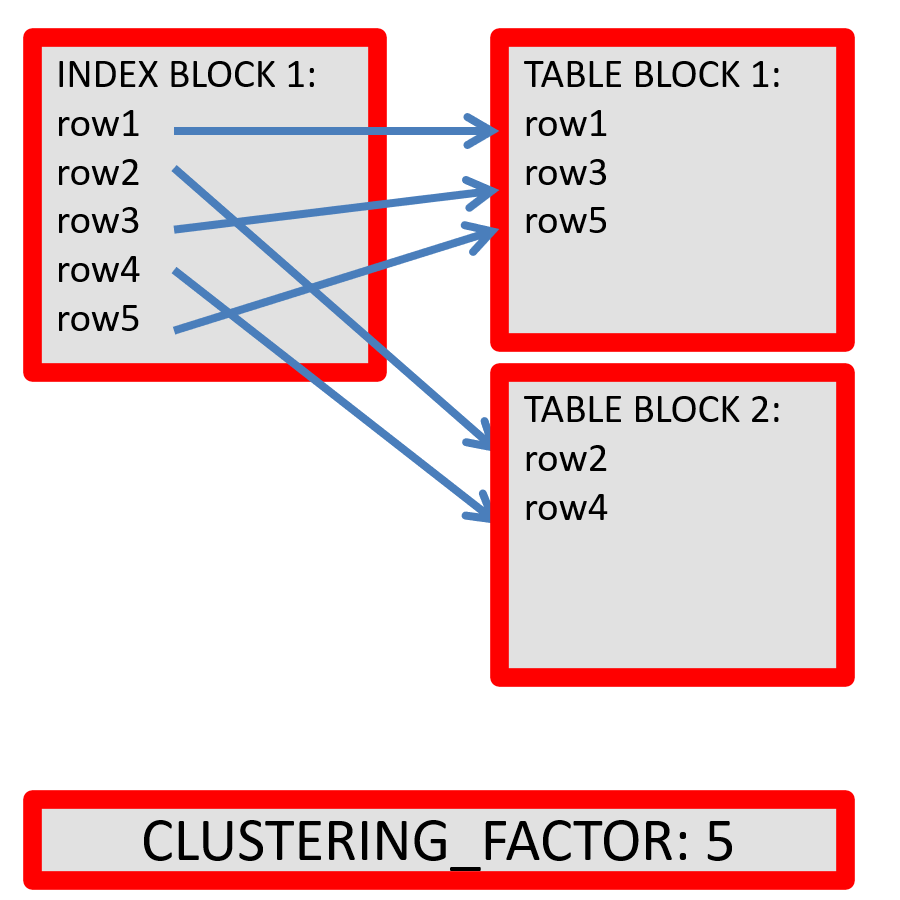
Oracle calculates the clustering factor when it gathers statistics, as we can see in the 2 diagrams above.
To check this, I created a table and procedure, and ran the procecure in 3 seperate sessions simultaneously (this is important, as ASSM will assign different blocks to each session on insert, so adjacent values can be in different blocks to lower block contention – the way it tends to happen in multi-user systems).
CREATE SEQUENCE cost_tab_seq;CREATE TABLE cost_tab (id number NOT NULL, data number NOT NULL, force_tab_lookup_col VARCHAR2(20) NOT NULL);ALTER TABLE cost_tab ADD CONSTRAINT cost_tab_pk PRIMARY KEY (ID);CREATE OR REPLACE PROCEDURE cost_tab_data as begin for ii in 1..1000000 loop insert into cost_tab values (cost_tab_seq.nextval, mod(ii,1000), 'need_tab_access'); commit; end loop; end;/Session1: EXEC cost_tab_dataSession2: EXEC cost_tab_dataSession3: EXEC cost_tab_data > SELECT table_name,num_rows,blocks,avg_row_len,floor(8192/avg_row_len) rows_per_block FROM user_tab_statistics WHERE table_name = 'COST_TAB';TABLE_NAME NUM_ROWS BLOCKS AVG_ROW_LEN ROWS_PER_BLOCK---------- ---------- ---------- ----------- --------------COST_TAB 3000000 13157 26 315 > SELECT table_name,index_name,num_rows,leaf_blocks,clustering_factor FROM user_ind_statistics WHERE index_name = 'COST_TAB_PK';TABLE_NAME INDEX_NAME NUM_ROWS LEAF_BLOCKS CLUSTERING_FACTOR---------- ------------ ---------- ----------- -----------------COST_TAB COST_TAB_PK 2929815 8463 2102277
We can take a look at a table manually and see which row relates to which block.
As we can see below, the inserts flipped between using block 2530 and 2533.
SELECT id ,DBMS_ROWID.ROWID_BLOCK_NUMBER (rowid) blk FROM cost_tab WHERE id BETWEEN 8000 and 8050 ORDER BY id; ID BLK---------- ---------- 8000 2530 8001 2533 8002 2530 8003 2530 8004 2533 8005 2530 8006 2530 8007 2533 8008 2530 8009 2530 8010 2533 8011 2530 8012 2530 8013 2533 8014 2530 8015 2530...
This caused the CLUSTERING_FACTOR (2102277) to be similar to the NUM_ROWS (2929815), meaning this is perceived by Oracle to be an expensive index. Lets do a query (with table access) and see what happens.
> set autotrace traceonly > SELECT id,data,force_tab_lookup_col FROM cost_tab WHERE id BETWEEN 1000 AND 10000;9001 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 546684077------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 9002 | 228K| 3580 (1)| 00:00:01 ||* 1 | TABLE ACCESS FULL| COST_TAB | 9002 | 228K| 3580 (1)| 00:00:01 |------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 1 - filter("ID"<=10000 AND "ID">=1000)
The perception that the index is EXPENSIVE mean Oracle has decided that a FULL TABLE SCAN is more efficient than using the index. However, we can see by looking at the relationship between the ROW and the BLOCK that the CLUSTERING FACTOR is being somewhat misrepresented.
By default (even in 26ai), the clustering factor expects only 1 table block to be cached, so if the block being read changes, the clustering factor increases. Fortunately we do have some control over this. We can tell Oracle to only increment the clustering factor if the block being accessed did not appear in the last N number of blocks using the table preference “TABLE_CACHED_BLOCKS“.
Lets change that preference so Oracle thinks that there are 16 blocks in the cache (a good place to start), regather stats and re-run the test.
-- set table_cached_blocks> EXEC DBMS_STATS.SET_TABLE_PREFS(USER,'COST_TAB','TABLE_CACHED_BLOCKS',16);PL/SQL procedure successfully completed.-- gather stats> EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'COST_TAB');PL/SQL procedure successfully completed.-- check values> SELECT * FROM user_tab_stat_prefs;TABLE_NAME PREFERENCE_NAME PREFERENCE_VALUE---------- ------------------------------ ------------------------------COST_TAB TABLE_CACHED_BLOCKS 16> SELECT table_name,num_rows,blocks,avg_row_len,floor(8192/avg_row_len) rows_per_block FROM user_tab_statistics WHERE table_name = 'COST_TAB';TABLE_NAME NUM_ROWS BLOCKS AVG_ROW_LEN ROWS_PER_BLOCK---------- ---------- ---------- ----------- --------------COST_TAB 3000000 13157 26 315-- we can see that the CLUSTERING_FACTOR has changed from-- 2102277 to 29418 > SELECT table_name,index_name,num_rows,leaf_blocks,clustering_factor FROM user_ind_statistics WHERE index_name like 'COST_TAB%' ORDER BY INDEX_NAME;TABLE_NAME INDEX_NAME NUM_ROWS LEAF_BLOCKS CLUSTERING_FACTOR---------- ------------ ---------- ----------- -----------------COST_TAB COST_TAB_PK 2775962 8020 29418> set autotrace traceonly> SELECT id,data,force_tab_lookup_col FROM cost_tab WHERE id BETWEEN 1000 AND 10000;9001 rows selected.Execution Plan----------------------------------------------------------Plan hash value: 2824852897---------------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |---------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 9002 | 228K| 129 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID BATCHED| COST_TAB | 9002 | 228K| 129 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | COST_TAB_PK | 9002 | | 30 (0)| 00:00:01 |---------------------------------------------------------------------------------------------------
Looking at the new execution plan, we chave changed from a FULL TABLE SCAN to an INDEX RANGE SCAN, with a batched table lookup by rowid. We are using the index because the clustering factor is much closer to the number of blocks in the table, and the index is perceived as closely aligned to the table and therefore a better access path candidate.
The COST has dramatically reduced from 3580 to 129.
Nothing else changed, except we told Oracle that we may have more table blocks in the buffer cache so we should account for that in the clustering factor.
Recommendation
There’s a good chance that a table will have more than 1 blocks cached, so setting TABLE_CACHED_BLOCKS to more than 1 will produce a much more realistic figure for clustering factor than leaving it to default. You can either do this on a table-by-table basis, or set it globally as follows.
> SELECT banner_full FROM v$version;BANNER_FULL--------------------------------------------------------------------------------Oracle AI Database 26ai Enterprise Edition Release 23.26.1.0.0 - ProductionVersion 23.26.1.0.0> SELECT dbms_stats.get_prefs('TABLE_CACHED_BLOCKS');DBMS_STATS.GET_PREFS('TABLE_CACHED_BLOCKS')--------------------------------------------------------------------------------1> exec DBMS_STATS.SET_GLOBAL_PREFS('TABLE_CACHED_BLOCKS',16);PL/SQL procedure successfully completed.> SELECT dbms_stats.get_prefs('TABLE_CACHED_BLOCKS');DBMS_STATS.GET_PREFS('TABLE_CACHED_BLOCKS')--------------------------------------------------------------------------------16
Setting it to 16 is a good place to start, or maybe 16 * Instances in the RAC cluster.
WARNING!
If you REBUILD an index the stats are re-gathered during the rebuild and any setting of TABLE_CACHED_BLOCKS is ignored for these stats! If you rebuild an index, you may just want to regather stats immediately afterwards.
> SELECT table_name,index_name,num_rows,leaf_blocks,clustering_factor FROM user_ind_statistics WHERE index_name = 'COST_TAB_PK' ;TABLE_NAME INDEX_NAME NUM_ROWS LEAF_BLOCKS CLUSTERING_FACTOR---------- ------------ ---------- ----------- -----------------COST_TAB COST_TAB_PK 3006003 6547 25937> ALTER INDEX COST_TAB_PK REBUILD;Index altered.> SELECT table_name,index_name,num_rows,leaf_blocks,clustering_factor FROM user_ind_statistics WHERE index_name = 'COST_TAB_PK' ; TABLE_NAME INDEX_NAME NUM_ROWS LEAF_BLOCKS CLUSTERING_FACTOR---------- ------------- ---------- ----------- -----------------COST_TAB COST_TAB_PK 3000000 6542 2147697> EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'COST_TAB',ESTIMATE_PERCENT=>DBMS_STATS.AUTO_SAMPLE_SIZE);PL/SQL procedure successfully completed.> SELECT table_name,index_name,num_rows,leaf_blocks,clustering_factor FROM user_ind_statistics WHERE index_name = 'COST_TAB_PK' ;TABLE_NAME INDEX_NAME NUM_ROWS LEAF_BLOCKS CLUSTERING_FACTOR---------- ------------ ---------- ----------- -----------------COST_TAB COST_TAB_PK 3037807 6634 25850
Some Other Related Thoughts
Rebuilding indexes does NOT change the clustering factor. This is the relationship between the index and the table and the order of data within the table has not changed.
Generally speaking, rebuilding indexes in Oracle is rarely useful. In over 30 years, I’ve only implemented it on a couple of indexes which had a long thin tail of undeleted data. Rebuilding might make things worse for updates and inserts in the short term, as rebuilding the index can compact the index meaning you get excessive index block splits as you add and change data until the index settles back to normal.
You can rebuild the table with the data ordered on a different columns (e.g. the column you’re indexing), BUT this will have side effects. Your index will get a different and potentially excellent clustering factor, but the clustering factor of other indexes will probably degrade.
Only Statistics…
Please remember this is only about making statistics for indexes more accurate. For more awesome performance benefits, you might want to consider clustering your data







Leave a comment